The Data Repository Service (DRS) API provides a generic interface to data repositories so data consumers, including workflow systems, can access data objects in a single, standard way regardless of where they are stored and how they are managed. The primary functionality of DRS is to map a logical ID to a means for physically retrieving the data represented by the ID. The sections below describe the characteristics of those IDs, the types of data supported, how they can be pointed to using URIs, and how clients can use these URIs to ultimately make successful DRS API requests. This document also describes the DRS API in detail and provides information on the specific endpoints, request formats, and responses. This specification is intended for developers of DRS-compatible services and of clients that will call these DRS services.
The key words MUST, MUST NOT, REQUIRED, SHALL, SHALL NOT, SHOULD, SHOULD NOT, RECOMMENDED, MAY, and OPTIONAL in this document are to be interpreted as described in RFC 2119.
Each implementation of DRS can choose its own id scheme, as long as it follows these guidelines:
- DRS IDs are strings made up of uppercase and lowercase letters, decimal digits, hypen, period, underscore and tilde [A-Za-z0-9.-_~]. See RFC 3986 § 2.3.
- DRS IDs can contain other characters, but they MUST be encoded into valid DRS IDs whenever they are used in API calls. This is because non-encoded IDs may interfere with the interpretation of the objects/{id}/access endpoint. To overcome this limitation use percent-encoding of the ID, see RFC 3986 § 2.4
- One DRS ID MUST always return the same object data (or, in the case of a collection, the same set of objects). This constraint aids with reproducibility.
- DRS implementations MAY have more than one ID that maps to the same object.
- DRS version 1.x does NOT support semantics around multiple versions of an object. (For example, there’s no notion of “get latest version” or “list all versions”.) Individual implementations MAY choose an ID scheme that includes version hints.
For convenience, including when passing content references to a WES server, we define a URI scheme for DRS-accessible content. This section documents the syntax of DRS URIs, and the rules clients follow for translating a DRS URI into a URL that they use for making the DRS API calls described in this spec.
There are two styles of DRS URIs, Hostname-based and Compact Identifier-based, both using the drs:// URI scheme. DRS servers may choose either style when exposing references to their content;. DRS clients MUST support resolving both styles.
Tip:
See Appendix: Background Notes on DRS URIs for more information on our design motivations for DRS URIs.
Hostname-based DRS URIs
Hostname-based DRS URIs are simpler than compact identifier-based URIs. They contain the DRS server name and the DRS ID only and can be converted directly into a fetchable URL based on a simple rule. They take the form:
drs://<hostname>/<id>DRS URIs of this form mean "you can fetch the content with DRS id <id> from the DRS server at <hostname>". For example, here are the client resolution steps if the URI is:
drs://drs.example.org/314159- The client parses the string to extract the hostname of “drs.example.org” and the id of “314159”.
- The client makes a GET request to the DRS server, using the standard DRS URL syntax:
GET https://drs.example.org/ga4gh/drs/v1/objects/314159The protocol is always https and the port is always the standard 443 SSL port. It is invalid to include a different port in a DRS hostname-based URI.
Tip:
See the Appendix: Hostname-Based URIs for information on how hostname-based DRS URI resolution to URLs is likely to change in the future, when the DRS v2 major release happens.
Compact Identifier-based DRS URIs
Compact Identifier-based DRS URIs use resolver registry services (specifically, identifiers.org and n2t.net (Name-To-Thing)) to provide a layer of indirection between the DRS URI and the DRS server name — the actual DNS name of the DRS server isn’t present in the URI. This approach is based on the Joint Declaration of Data Citation Principles as detailed by Wimalaratne et al (2018).
For more information, see the document More Background on Compact Identifiers.
Compact Identifiers take the form:
drs://[provider_code/]namespace:accessionTogether, provider code and the namespace are referred to as the prefix. The provider code is optional and is used by identifiers.org/n2t.net for compact identifier resolver mirrors. Both the provider_code and namespace disallow spaces or punctuation, only lowercase alphanumerical characters, underscores and dots are allowed (e.g. [A-Za-z0-9._]).
Tip:
See the Appendix: Compact Identifier-Based URIs for more background on Compact Identifiers and resolver registry services like identifiers.org/n2t.net (aka meta-resolvers), how to register prefixes, possible caching strategies, and security considerations.
For DRS Servers
If your DRS implementation will issue DRS URIs based on your own compact identifiers, you MUST first register a new prefix with identifiers.org (which is automatically mirrored to n2t.net). You will also need to include a provider resolver resource in this registration which links the prefix to your DRS server, so that DRS clients can get sufficient information to make a successful DRS GET request. For clarity, we recommend you choose a namespace beginning with drs.
For DRS Clients
A DRS client parses the DRS URI compact identifier components to extract the prefix and the accession, and then uses meta-resolver APIs to locate the actual DRS server. For example, here are the client resolution steps if the URI is:
drs://drs.42:314159The client parses the string to extract the prefix of
drs.42and the accession of314159, using the first occurrence of a colon (":") character after the initialdrs://as a delimiter. (The colon character is not allowed in a Hostname-based DRS URI, making it easy to tell them apart.)The client makes API calls to a meta-resolver to look up the URL pattern for the namespace. (See Calling Meta-Resolver APIs for Compact Identifier-Based DRS URIs for details.) The URL pattern is a string containing a
{$id}parameter, such as:
https://drs.myexample.org/ga4gh/drs/v1/objects/{$id}- The client generates a DRS URL from the URL template by replacing {$id} with the accession it extracted in step 1. It then makes a GET request to the DRS server:
GET https://drs.myexample.org/ga4gh/drs/v1/objects/314159- The client follows any HTTP redirects returned in step 3, in case the resolver goes through an extra layer of redirection.
For performance reasons, DRS clients SHOULD cache the URL pattern returned in step 2, with a suggested 24 hour cache life.
Choosing a URI Style
DRS servers can choose to issue either hostname-based or compact identifier-based DRS URIs, and can be confident that compliant DRS clients will support both. DRS clients must be able to accommodate both URI types. Tradeoffs that DRS server builders, and third parties who need to cite DRS objects in datasets, workflows or elsewhere, may want to consider include:
Table 1: Choosing a URI Style
| Hostname-based | Compact Identifier-based | |
|---|---|---|
| URI Durability | URIs are valid for as long as the server operator maintains ownership of the published DNS address. (They can of course point that address at different physical serving infrastructure as often as they’d like.) | URIs are valid for as long as the server operator maintains ownership of the published compact identifier resolver namespace. (They also depend on the meta-resolvers like identifiers.org/n2t.net remaining operational, which is intended to be essentially forever.) |
| Client Efficiency | URIs require minimal client logic, and no network requests, to resolve. | URIs require small client logic, and 1-2 cacheable network requests, to resolve. |
| Security | Servers have full control over their own security practices. | Server operators, in addition to maintaining their own security practices, should confirm they are comfortable with the resolver registry security practices, including protection against denial of service and namespace-hijacking attacks. (See the Appendix: Compact Identifier-Based URIs for more information on resolver registry security.) |
DRS v1 supports two types of content:
- a blob is like a file — it’s a single blob of bytes, represented by a
DrsObjectwithout acontentsarray - a bundle is like a folder — it’s a collection of other DRS content (either blobs or bundles), represented by a
DrsObjectwith acontentsarray
DRS v1 is a read-only API. We expect that each implementation will define its own mechanisms and interfaces (graphical and/or programmatic) for adding and updating data.
The DRS API specification is written in OpenAPI and embodies a RESTful service philosophy. It uses JSON in requests and responses and standard HTTPS on port 443 for information transport.
The DRS implementation is responsible for defining and enforcing an authorization policy that determines which users are allowed to make which requests. GA4GH recommends that DRS implementations use an OAuth 2.0 bearer token, although they can choose other mechanisms if appropriate.
The DRS API allows implementers to support a variety of different content access policies, depending on what AccessMethod records they return:
- public content:
- server provides an
access_urlwith aurland noheaders - caller fetches the object bytes without providing any auth info
- server provides an
- private content that requires the caller to have out-of-band auth knowledge (e.g. service account credentials):
- server provides an
access_urlwith aurland noheaders - caller fetches the object bytes, passing the auth info they obtained out-of-band
- server provides an
- private content that requires the caller to pass an Authorization token:
- server provides an
access_urlwith aurlandheaders - caller fetches the object bytes, passing auth info via the specified header(s)
- server provides an
- private content that uses an expensive-to-generate auth mechanism (e.g. a signed URL):
- server provides an
access_id - caller passes the
access_idto the/accessendpoint - server provides an
access_urlwith the generated mechanism (e.g. a signed URL in theurlfield) - caller fetches the object bytes from the
url(passing auth info from the specified headers, if any)
- server provides an
DRS implementers should ensure their solutions restrict access to targets as much as possible, detect attempts to exploit through log monitoring, and they are prepared to take action if an exploit in their DRS implementation is detected.
BasicAuth
A valid authorization token must be passed in the 'Authorization' header, e.g. "Basic ${token_string}"
| Security Scheme Type | HTTP |
|---|---|
| HTTP Authorization Scheme | basic |
BearerAuth
A valid authorization token must be passed in the 'Authorization' header, e.g. "Bearer ${token_string}"
| Security Scheme Type | HTTP |
|---|---|
| HTTP Authorization Scheme | bearer |
Get info about a DrsObject.
Returns object metadata, and a list of access methods that can be used to fetch object bytes.
Authorizations:
path Parameters
| object_id required | string
|
query Parameters
| expand | boolean If false and the object_id refers to a bundle, then the ContentsObject array contains only those objects directly contained in the bundle. That is, if the bundle contains other bundles, those other bundles are not recursively included in the result. If true and the object_id refers to a bundle, then the entire set of objects in the bundle is expanded. That is, if the bundle contains aother bundles, then those other bundles are recursively expanded and included in the result. Recursion continues through the entire sub-tree of the bundle. If the object_id refers to a blob, then the query parameter is ignored. |
Responses
Response samples
- 200
- 400
- 401
- 403
- 404
- 500
{- "id": "string",
- "name": "string",
- "self_uri": "drs://drs.example.org/314159",
- "size": 0,
- "created_time": "2019-08-24T14:15:22Z",
- "updated_time": "2019-08-24T14:15:22Z",
- "version": "string",
- "mime_type": "application/json",
- "checksums": [
- {
- "checksum": "string",
- "type": "sha-256"
}
], - "access_methods": [
- {
- "type": "s3",
- "access_url": {
- "url": "string",
- "headers": "Authorization: Basic Z2E0Z2g6ZHJz"
}, - "access_id": "string",
- "region": "us-east-1"
}
], - "contents": [
- {
- "name": "string",
- "id": "string",
- "drs_uri": "drs://drs.example.org/314159",
- "contents": [
- { }
]
}
], - "description": "string",
- "aliases": [
- "string"
]
}Get a URL for fetching bytes
Returns a URL that can be used to fetch the bytes of a DrsObject.
This method only needs to be called when using an AccessMethod that contains an access_id (e.g., for servers that use signed URLs for fetching object bytes).
Authorizations:
path Parameters
| object_id required | string
|
| access_id required | string An |
Responses
Response samples
- 200
- 400
- 401
- 403
- 404
- 500
{- "url": "string",
- "headers": "Authorization: Basic Z2E0Z2g6ZHJz"
}| type required | string Enum: "s3" "gs" "ftp" "gsiftp" "globus" "htsget" "https" "file" Type of the access method. |
object (AccessURL) | |
| access_id | string An arbitrary string to be passed to the |
| region | string Name of the region in the cloud service provider that the object belongs to. |
{- "type": "s3",
- "access_url": {
- "url": "string",
- "headers": "Authorization: Basic Z2E0Z2g6ZHJz"
}, - "access_id": "string",
- "region": "us-east-1"
}| url required | string A fully resolvable URL that can be used to fetch the actual object bytes. |
| headers | Array of strings An optional list of headers to include in the HTTP request to |
{- "url": "string",
- "headers": "Authorization: Basic Z2E0Z2g6ZHJz"
}| checksum required | string The hex-string encoded checksum for the data |
| type required | string The digest method used to create the checksum.
The value (e.g. |
{- "checksum": "string",
- "type": "sha-256"
}| name required | string A name declared by the bundle author that must be used when materialising this object, overriding any name directly associated with the object itself. The name must be unique with the containing bundle. This string is made up of uppercase and lowercase letters, decimal digits, hypen, period, and underscore [A-Za-z0-9.-_]. See http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap03.html#tag_03_282[portable filenames]. |
| id | string A DRS identifier of a |
| drs_uri | Array of strings A list of full DRS identifier URI paths that may be used to obtain the object. These URIs may be external to this DRS instance. |
Array of objects (ContentsObject) If this ContentsObject describes a nested bundle and the caller specified "?expand=true" on the request, then this contents array must be present and describe the objects within the nested bundle. |
{- "name": "string",
- "id": "string",
- "drs_uri": "drs://drs.example.org/314159",
- "contents": [
- { }
]
}| id required | string An identifier unique to this |
| name | string A string that can be used to name a |
| self_uri required | string A drs:// hostname-based URI, as defined in the DRS documentation, that tells clients how to access this object.
The intent of this field is to make DRS objects self-contained, and therefore easier for clients to store and pass around. For example, if you arrive at this DRS JSON by resolving a compact identifier-based DRS URI, the |
| size required | integer <int64> For blobs, the blob size in bytes.
For bundles, the cumulative size, in bytes, of items in the |
| created_time required | string <date-time> Timestamp of content creation in RFC3339. (This is the creation time of the underlying content, not of the JSON object.) |
| updated_time | string <date-time> Timestamp of content update in RFC3339, identical to |
| version | string A string representing a version. (Some systems may use checksum, a RFC3339 timestamp, or an incrementing version number.) |
| mime_type | string A string providing the mime-type of the |
required | Array of objects (Checksum) non-empty The checksum of the |
Array of objects (AccessMethod) non-empty The list of access methods that can be used to fetch the | |
Array of objects (ContentsObject) If not set, this | |
| description | string A human readable description of the |
| aliases | Array of strings A list of strings that can be used to find other metadata about this |
{- "id": "string",
- "name": "string",
- "self_uri": "drs://drs.example.org/314159",
- "size": 0,
- "created_time": "2019-08-24T14:15:22Z",
- "updated_time": "2019-08-24T14:15:22Z",
- "version": "string",
- "mime_type": "application/json",
- "checksums": [
- {
- "checksum": "string",
- "type": "sha-256"
}
], - "access_methods": [
- {
- "type": "s3",
- "access_url": {
- "url": "string",
- "headers": "Authorization: Basic Z2E0Z2g6ZHJz"
}, - "access_id": "string",
- "region": "us-east-1"
}
], - "contents": [
- {
- "name": "string",
- "id": "string",
- "drs_uri": "drs://drs.example.org/314159",
- "contents": [
- { }
]
}
], - "description": "string",
- "aliases": [
- "string"
]
}| msg | string A detailed error message. |
| status_code | integer The integer representing the HTTP status code (e.g. 200, 404). |
{- "msg": "string",
- "status_code": 0
}| Data sharing requires portable data, consistent with the FAIR data principles (findable, accessible, interoperable, reusable). Today’s researchers and clinicians are surrounded by potentially useful data, but often need bespoke tools and processes to work with each dataset. Today’s data publishers don’t have a reliable way to make their data useful to all (and only) the people they choose. And today’s data controllers are tasked with implementing standard controls of non-standard mechanisms for data access. |
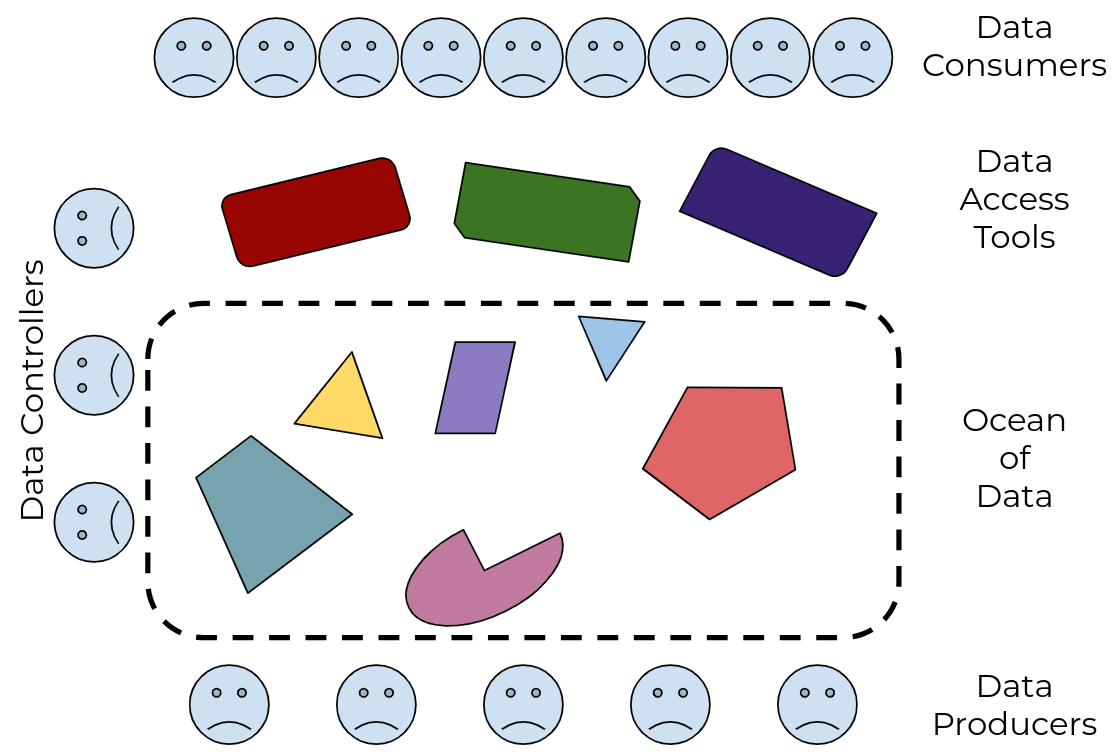 Figure 1: there’s an ocean of data, with many different tools to drink from it, but no guarantee that any tool will work with any subset of the data
Figure 1: there’s an ocean of data, with many different tools to drink from it, but no guarantee that any tool will work with any subset of the data
|
| We need a standard way for data producers to make their data available to data consumers, that supports the control needs of the former and the access needs of the latter. And we need it to be interoperable, so anyone who builds access tools and systems can be confident they’ll work with all the data out there, and anyone who publishes data can be confident it will work with all the tools out there. |
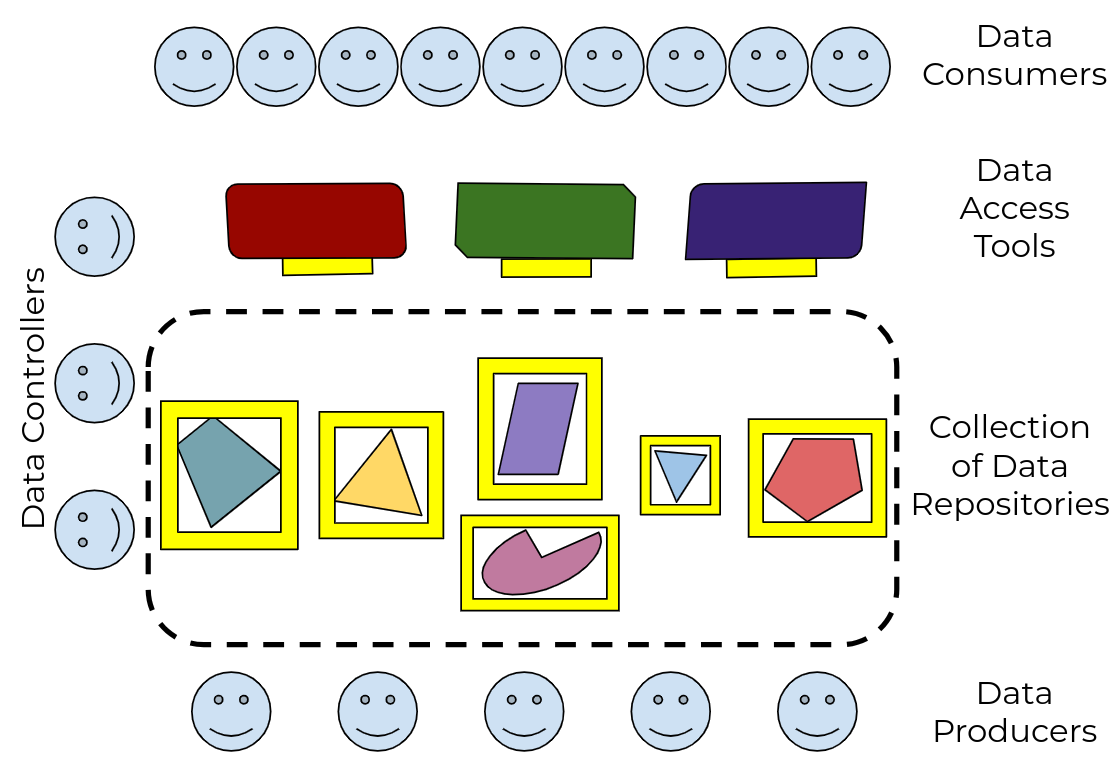 Figure 2: by defining a standard Data Repository API, and adapting tools to use it, every data publisher can now make their data useful to every data consumer
Figure 2: by defining a standard Data Repository API, and adapting tools to use it, every data publisher can now make their data useful to every data consumer
|
We envision a world where:
|
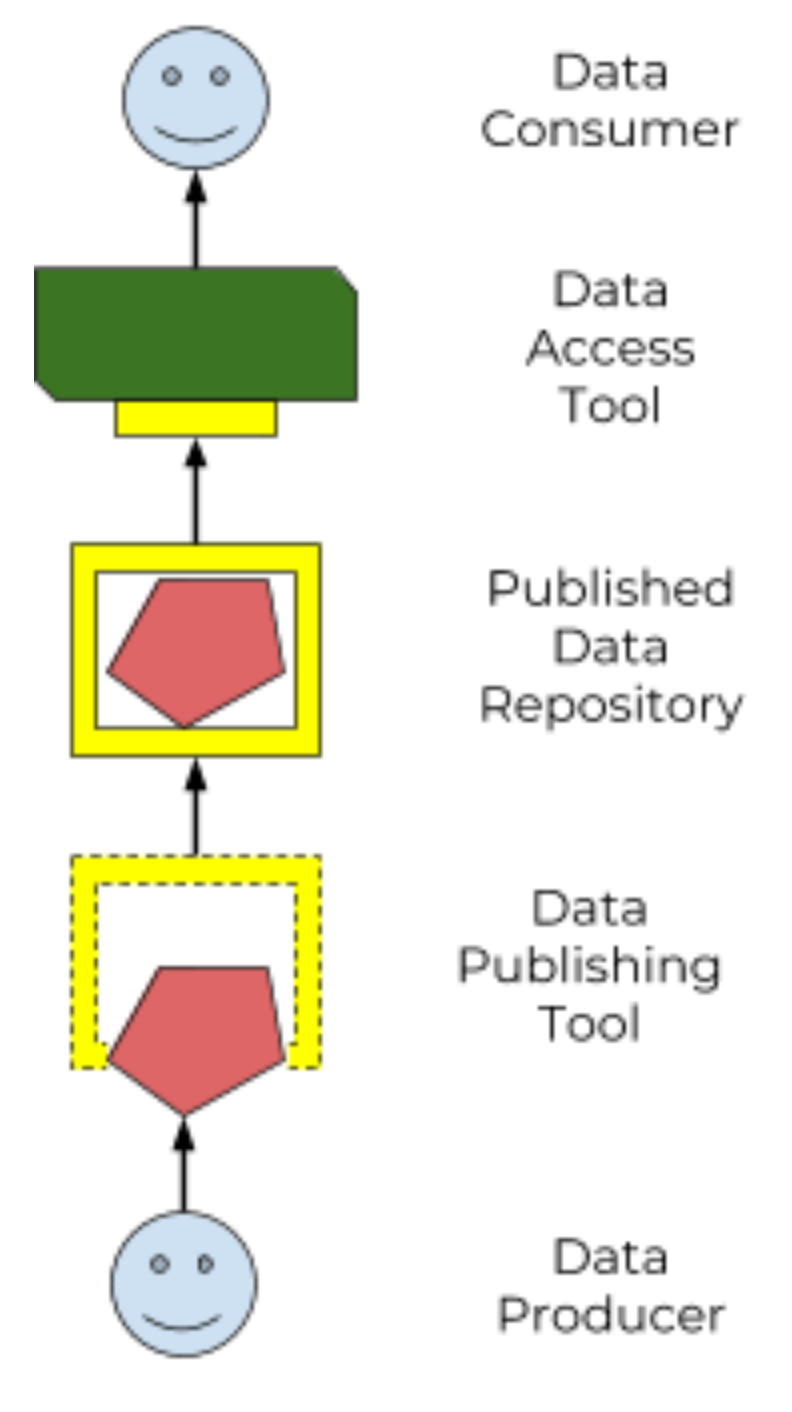 Figure 3: a standard Data Repository API enables an ecosystem of data producers and consumers
Figure 3: a standard Data Repository API enables an ecosystem of data producers and consumers
|
This spec defines a standard Data Repository Service (DRS) API (“the yellow box”), to enable that ecosystem of data producers and consumers. Our goal is that the only thing data consumers need to know about a data repo is "here’s the DRS endpoint to access it", and the only thing data publishers need to know to tap into the world of consumption tools is "here’s how to tell it where my DRS endpoint lives".
The world’s biomedical data is controlled by groups with very different policies and restrictions on where their data lives and how it can be accessed. A primary purpose of DRS is to support unified access to disparate and distributed data. (As opposed to the alternative centralized model of "let’s just bring all the data into one single data repository”, which would be technically easier but is no more realistic than “let’s just bring all the websites into one single web host”.)
In a DRS-enabled world, tool builders don’t have to worry about where the data their tools operate on lives — they can count on DRS to give them access. And tool users only need to know which DRS server is managing the data they need, and whether they have permission to access it; they don’t have to worry about how to physically get access to, or (worse) make a copy of the data. For example, if I have appropriate permissions, I can run a pooled analysis where I run a single tool across data managed by different DRS servers, potentially in different locations.
DRS URIs are aligned with the FAIR data principles and the Joint Declaration of Data Citation Principles — both hostname-based and compact identifier-based URIs provide globally unique, machine-resolvable, persistent identifiers for data.
- We require all URIs to begin with
drs://as a signal to humans and systems consuming these URIs that the response they will ultimately receive, after transforming the URI to a fetchable URL, will be a DRS JSON packet. This signal differentiates DRS URIs from the wide variety of other entities (HTML documents, PDFs, ontology notes, etc.) that can be represented by compact identifiers. - We support hostname-based URIs because of their simplicity and efficiency for server and client implementers.
- We support compact identifier-based URIs, and the meta-resolver services of identifiers.org and n2t.net (Name-to-Thing), because of the wide adoption of compact identifiers in the research community. as detailed by Wimalaratne et al (2018) in "Uniform resolution of compact identifiers for biomedical data."
Note: Identifiers.org/n2t.net API Changes
The examples below show the current API interactions with n2t.net and identifiers.org which may change over time. Please refer to the documentation from each site for the most up-to-date information. We will make best efforts to keep the DRS specification current but DRS clients MUST maintain their ability to use either the identifiers.org or n2t.net APIs to resolve compact identifier-based DRS URIs.
See the documentation on the n2t.net and identifiers.org meta-resolvers for adding your own compact identifier type and registering your DRS server as a resolver. You can register new prefixes (or mirrors by adding resource provider codes) for free using a simple online form. For more information see More Background on Compact Identifiers.
Clients resolving Compact Identifier-based URIs need to convert a prefix (e.g. “drs.42”) into an URL pattern. They can do so by calling either the identifiers.org or the n2t.net API, since the two meta-resolvers keep their mapping databases in sync.
Calling the identifiers.org API as a Client
It takes two API calls to get the URL pattern.
- The client makes a GET request to identifiers.org to find information about the prefix:
GET https://registry.api.identifiers.org/restApi/namespaces/search/findByPrefix?prefix=drs.42This request returns a JSON structure including various URLs containing an embedded namespace id, such as:
"namespace" : {
"href":"https://registry.api.identifiers.org/restApi/namespaces/1234"
}- The client extracts the namespace id (in this example 1234), and uses it to make a second GET request to identifiers.org to find information about the namespace:
GET https://registry.api.identifiers.org/restApi/resources/search/findAllByNamespaceId?id=1234This request returns a JSON structure including an urlPattern field, whose value is an URL pattern containing a ${id} parameter, such as:
"urlPattern" : "https://drs.myexample.org/ga4gh/drs/v1/objects/{$id}"Calling the n2t.net API as a Client
It takes one API call to get the URL pattern.
The client makes a GET request to n2t.net to find information about the namespace. (Note the trailing colon.)
GET https://n2t.net/drs.42:This request returns a text structure including a redirect field, whose value is an URL pattern containing a $id parameter, such as:
redirect: https://drs.myexample.org/ga4gh/drs/v1/objects/$idIdentifiers.org/n2t.net compact identifier resolver records do not change frequently. This reality is useful for caching resolver records and their URL patterns for performance reasons. Builders of systems that use compact identifier-based DRS URIs should cache prefix resolver records from identifiers.org/n2t.net and occasionally refresh the records (such as every 24 hours). This approach will reduce the burden on these community services since we anticipate many DRS URIs will be regularly resolved in workflow systems. Alternatively, system builders may decide to directly mirror the registries themselves, instructions are provided on the identifiers.org/n2t.net websites.
As mentioned earlier, identifiers.org/n2t.net performs some basic verification of new prefixes and provider code mirror registrations on their sites. However, builders of systems that consume and resolve DRS URIs may have certain security compliance requirements and regulations that prohibit relying on an external site for resolving compact identifiers. In this case, systems under these security and compliance constraints may wish to whitelist certain compact identifier resolvers and/or vet records from identifiers.org/n2t.net before enabling in their systems.
The compact identifier format used by identifiers.org/n2t.net does not percent-encode reserved URI characters but, instead, relies on the first ":" character to separate prefix from accession. Since these accessions can contain any characters, and characters like "/" will interfere with DRS API calls, you must percent encode the accessions extracted from DRS compact identifier-based URIs when using as DRS IDs in subsequent DRS GET requests. An easy way for a DRS client to handle this is to get the initial DRS object JSON response from whatever redirects the compact identifier resolves to, then look for the self_uri in the JSON, which will give you the correctly percent-encoded DRS ID for subsequent DRS API calls such as the access method.
For additional examples, see the document More Background on Compact Identifiers.
In hostname-based DRS URIs, the ID is always percent-encoded to ensure special characters do not interfere with subsequent DRS endpoint calls. As such, ":" is not allowed in the URI and is a convenient way of differentiating from a compact identifier-based DRS URI. Also, if a given DRS service implementation uses compact identifier accessions as their DRS IDs, they must be percent encoded before using them as DRS IDs in hostname-based DRS URIs and subsequent GET requests to a DRS service endpoint.
In the future, as new major versions of DRS are released, a DRS server might support multiple API versions on different URL paths. At that point we expect to add support for service-registry and service-info endpoints to the API, and to update the URI resolution logic to describe how to use those endpoints when translating hostname-based DRS URIs to URLs.